
1. Activation Functions

① Sigmoid

- 출력값을 0에서 1사이의 확률값으로 나타낸다.
[단점]
- (Saturation problem) Input x가 매우 크거나 작으면 기울기가 0에 가까워져 gradient vanishing 문제가 일어나게 된다.
- (not zero-centered problem) Input x가 모두 양수이거나 모두 음수이면, Gradient W의 값도 항상 양수이거나 음수값이 된다. 이는 gradient W가 항상 같은 방향으로 움직인다는 것을 의미하고, 결국 비효율적으로 최적해를 탐색하게 된다.
② Tanh

- 출력값을 -1에서 1로 나타내어 zero-centered 문제를 해결해준다.
[단점]
- (Saturation Probelm) 여전히 saturation 구간이 있어서 gradient vanishing 문제가 있다.
③ ReLU

- 양의 값에서는 Satrurated 되지 않는다.
- sigmoid와 tanh보다 6배 정도 빠르다.
[단점]
- (not zero-centered Problem) zero-centered 가 아니라는 문제가 있다.
- (Saturation Problem) 음수 영역에서 saturated 되는 문제가 있다.
- ReLU가 DATA CLOUD로부터 떨어져 있을 때 Dead ReLU가 발생할 수 있다.

④ Leaky ReLU

- ReLU와 유사하지만, negative regime에서 0의 값이 아니다.
- 그래서 ReLU와 다르게 saturated 되지 않는다.
- 또한 Dead ReLU현상도 없다.
- Leaky ReLU와 유사한 PReLU라는 함수도 있는데 여기서는 기울기가 alpha라는 파라미터로 결정이 된다. alpha는 상수가 아니라 backprop으로 학습시키는 파라미터이다.
⑤ Exponential Linear Unit (ELU)

- 앞선 LU 그래프들과 다르게 ELU는 zero-mean에 가까운 출력값을 보인다.
[단점]
- Leaky ReLU와 비교해보면 ELU는 negative regime에서 Saturated되는 문제가 있다.
- 하지만 ELU 논문에서는 이런 Saturation이 좀 더 noise에 강인할 수 있다고 주장한다.
⑥ Scaled Exponential Linear Unit (SELU)

- ELU의 scale된 버젼
- "Self Normalization" 특성이 있어서 BatchNorm없이 SELU 네트워크를 학습시킬 수 있다.
⑦ Gaussian Error Linear Unit (GELU)


- 다양한 활성화 함수들이 있지만 실제로 가장 많이 쓰는 것은 ReLU이다.
- 다만 ReLU를 사용하려면 learning rate를 잘 조절해서 Dead ReLU에 빠지지 않게 해야 한다.
2. Data Preprocessing

- normalization을 하는 이유는 모든 차원이 동일한 범위안에 있게 해줘서 전부 동등한 contribute를 하기 위함이다.
- 또한 정규화를 하면 weights의 작은 변화에 덜 민감하게 되고 최적화하기 쉬워진다.

- AlexNet은 전체 픽셀 값의 평균을 빼서 사용한다. -> zero-mean 전처리
- VGGNet은 채널별 픽셀 값의 평균을 빼서 사용한다. -> zero-mean 전처리
- ResNet은 채널별 픽셀 값의 평균을 빼고 채널별 픽셀 값의 표준편차를 나눠서 사용한다.
주로 preprocessing과 batch normalization을 사용한다.
3. Weight Initialization
'모든 가중치=0'이면 어떻게 될까?
모든 뉴런이 같은 일(같은 연산)을 하여 결국 gradient가 같을 것이고 모든 뉴런이 똑같이 업데이트 될 것이다.
<가중치 초기화 방법>
① Activation Statistics
: 작은 랜덤 값으로 초기화 시켜준다.
- 초기 W를 표준 정규분포에서 샘플링한다.
- 더 작은 값을 위해 평균이 0이고, 표준편차를 0.01인 가우시안 분포를 이용한다.

[단점]
Small data에서는 잘 작동하지만 activation 함수를 넣은 Deep Network에서는 잘 작동하지 않는다.

② Xavier Initialization
:

W = np.random.randn(Din, Dout) / np.sqrt(Din)
- Standard gaussian으로 뽑은 값을 '입력의 수'로 스케일링 해준다.
- 기본적으로 Xavier Initialization이 하는 일은 입/출력의 분산을 맞춰주는 것이다.

- 하지만 이 방법은 Linear activation이 있다고 가정한다.
- 그래서 ReLU를 사용하면 잘 작동하지 않는 문제점이 있다.
- ReLU는 출력의 negative region을 죽이기 때문에 출력의 분산을 반토막 내버리기 때문에 위와 같은 가정이 있는 한, ReLU에서는 잘 작동하지 않는다.
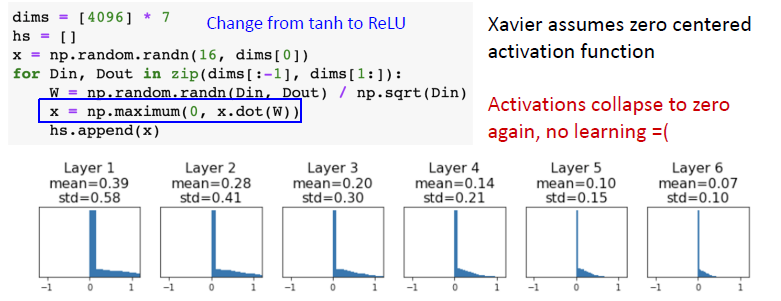
③ Kaiming / MSRA Initialization

- ReLU 의 nonlinear 문제를 해결하기 위해 std를 sqrt(1/Din)에서 sqrt(2/Din)으로 바꾼다.
- 이는 뉴런들 중 절반이 없어진다는 사실을 고려하기 위함이다.
④ Residual Networks

[Problem]
Residual Networks에서는 input의 분산과 output의 분산이 합쳐지기 때문에 activation의 분산이 계속 커지게 된다.
[Solution]
First layer는 MSRA initialize하고, Last layer는 0으로 초기화한다.
4. Regularization

① Add term to the loss

② Dropout

- [첫번째 해석] Feature의 co-adaptation을 막을 수 있다.
- 물체를 인식하는 데 서로 다른 부분을 robust한 방법으로 학습할 수 있다.
- 예를 들어 고양이를 인식할 때 Dropout을 적용해 어떤 뉴런들은 귀에 대해 학습하고, 어떤 뉴런들은 꼬리에 대해 학습하여, 서로 다른 뉴런들이 고양이의 각 부분을 더욱 잘 학습할 수 있게 해준다.
- [두번째 해석] Dropout은 아주 큰 앙상블을 학습한다.
- weights를 공유하고 있는 여러 sub network를 학습한다.
- [문제점] Dropout은 test time에서의 output을 랜덤하게 만든다.
- -> test시에 dropout을 좀 더 deterministic하게 만들 필요가 있다.


- [해결책] Test time에서는, drop을 하지 않고 dropout probability를 곱해서 사용한다.
- 각 뉴런의 scale을 모두 맞춰야 한다 : test time에서의 output = train time에서의 expected output


Q) Rescaling을 언제 할 것인가?
A) test time에는 시스템의 효율을 최대화해야 하기 때문에 rescale하지 않는게 좋다.
[A common pattern]

- Training을 할 때는 randomness을 더하지만, Testing 할 때는 randomness를 평균내서 사용한다.
- Batch Normalization을 예시로 들면, Training시에는 random minibatches의 통계값들을 사용하지만, Testing시에는 고정된 통계값들을 사용한다.
- ResNet 구조의 경우, 보통 Dropout 대신 L2 weight decay 또는 Batch Normalization을 regularizer로 사용한다.
④ DropConnect
: random activation을 랜덤으로 zeroing하는 것이 아니라, 랜덤으로 zero weight를 만든다.

⑤ Fractional Pooling

⑥ Stochastic Depth
: droping blocks

⑦ Mixup

5. Data Augmentation <- To make more diverse randomness examples
① Random Crops and Scales

② Color Jitter

[A common pattern]

6. 정리
- Consider Dropout for large fully-connected layers
- Batch normalization and data augmentation almost always a good idea
- Try cutout and mixup especially for small classification datasets
'Open Lecture Review > Deep Learning for Computer Vision' 카테고리의 다른 글
| Lec12_Recurrent Neural Networks (0) | 2022.02.14 |
|---|---|
| Lecture 11_Training Neural Networks 2 (0) | 2022.02.13 |
| Lec8_CNN Architectures (0) | 2022.02.07 |
| Lec7_ Convolutional Networks (0) | 2022.01.24 |
| Lec6_Backpropagation (0) | 2022.01.24 |



