1. AlexNet
[구조]
일부가 max-pooling layer가 적용된 5개의 convolutional layer와 3개의 full-connected layer로 이루어져 있다.

[특징]
- ReLU Nonlinearity
- 활성화 함수로 ReLU를 적용했다.
- 논문에서는 saturating nonlinearity (tanh, sigmoid)보다 non-saturating nonlinearity(ReLU)의 학습 속도가 몇배는 빠르다고 나와 있다.
- 4층의 CNN으로 CIFAR-10을 학습시켰을 때 ReLU가 tanh보다 6배 정도 빠르다.
- Training on Multiple GPUs
- network를 2개의 GPU로 나누어서 학습했다.
- 이를 GPU parallelization이라고 한다.
- 논문에서는 2개의 GPU로 나누어서 학습 시켜 학습 속도가 빨라졌을 뿐만 아니라 error도 감소되었다고 말한다.
- GPU1, GPU2 각각에서 학습된 kernel map으로 GPU1에서는 색상과 관련 없는 정보를 학습하고 GPU2는 색상과 과 관련된 정보를 학습하는 것을 확인할 수 있다.
- Local Respnse Normalization(LRN)
- LRN은 generalization(일반화)을 목적으로 한다.
- saturation문제가 있는 활성화 함수를 사용하면 vanishing gradient problem을 유발하게 되지만 ReLU는 saturating을 예방하기 위한 입력 normalization이 필요하지 않다는 성질이 있다.
- ReLU는 양수값을 받으면 그 값을 그대로 뉴런에 전달하기 때문에 너무 큰 값이 전달되어 낮은 값들이 뉴런에 전달되는 것을 막을 수 있다.
- 이를 예방하기 위한 것이 normalization LRN이고 논문에서 LRN을 측면 억제의 형태로 구현된다고 나와 있다.
- 측면 억제는 강한 자극이 주변의 약한 자극을 전달하는 것을 막는 효과를 말한다.
- 다만 AlexNet 이후 현대의 CNN에서는 local response normalization 대신 batch normalization기법을 사용한다.
- Overlapping pooling
- non-overlapping은 중첩없이 진행되는 모습이지만, overlapping은 중첩되는 모습으로 진행되어 overfitting을 방지한다.
- Data augmentation
- 현재 가지고 있는 데이터를 변형하여 다양한 데이터를 좀 더 얻는 것
- Alex Net에서 사용된 첫번째 기법은 generating image translation and horizontal reflection이다.
- 이 기법은 256x256 이미지를 수평 반전하고 224x224 크기로 random하게 crop하고, 생성된 이미지를 horizontal reflection을 하면 하나의 이미지에서 10개의 이미지를 생성할 수 있다.
- Alex Net에서 사용된 두번째 기법은 RGB channel의 강도 조절이다.
- RGB pixel 값들의 3x3 covariance matrix와 eigenvector와 eigenvalue에 랜덤 값인 알파를 곱해서 RGB image pixel에 더해줬다.
- Dropout
- train에서는 dropout을 적용시켰고 test에는 모든 neuron을 사용했지만 결과값에 0.5를 곱해서 사용했다.

2. ZFNet : A bigger AlexNet
: 이 모델의 주요 키워드는 visualizing이다. 학습된 모델이 무엇을 보고 있는지 나타내어 모델의 개선에 이용했다.
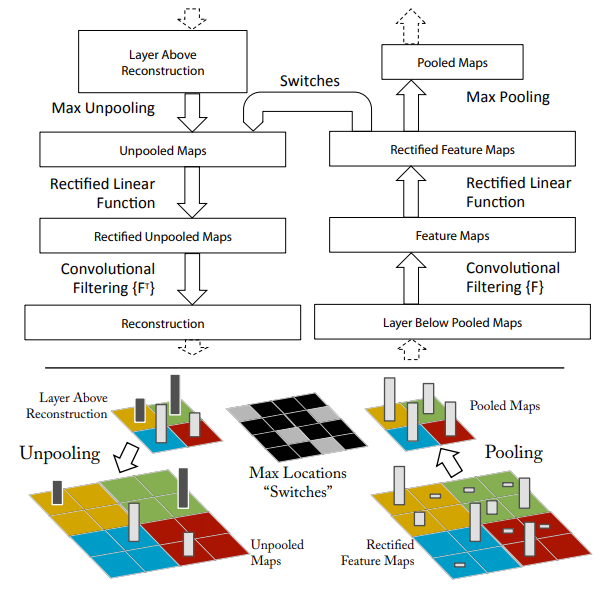
위 그림은 featuremap visualization을 위한 deconv과정이다. 왼쪽이 deconv의 일련의 과정이고, 오른쪽이 일반적인 CNN의 forward 과정이다. rectified feature map -> pooling -> conv -> relu -> pool의 과정을 나타낸다. 왼쪽은 반대로 위에서부터 max-unpool -> relu -> deconv -> max-unpool의 과정이다.

3. VGG
: 합성곱 계층과 풀링 계층으로 구성되는 기본적인 CNN
다만, 아래 그림과 같이 비중 있는 층 (Convolutional layer, fully-connected layer)을 모두 16층(혹은 19층)으로 심화한 것이 특징이다.
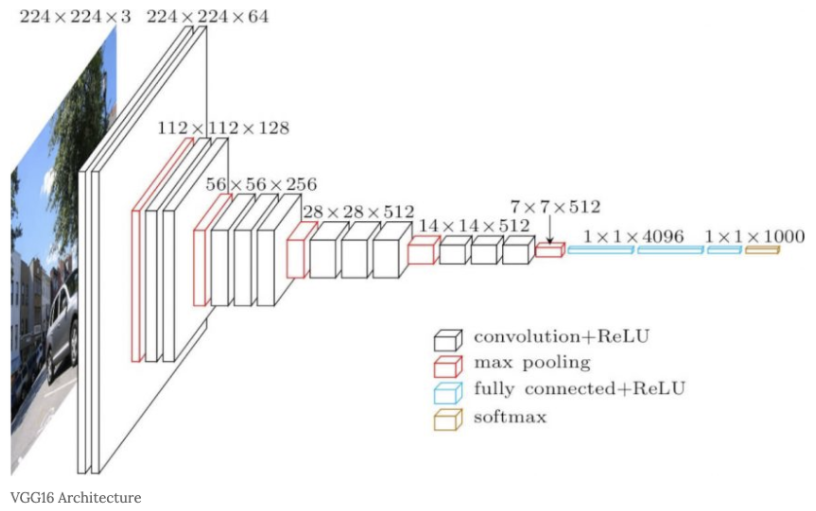
- GooLeNet에 근소한 차이로 밀려 2위를 차지했지만, 굉장히 간단한 구조로 이루어져 있어 딥러닝 모델의 깊이가 깊지 않아도 큰 성능을 낼 수 있다는 것을 보여준 의미있는 모델이다.
- 주목할 만한 점은 3x3의 작은 필터를 사용한 합성곱 계층을 연속으로 거친다는 것이다.
- 위와 같은 방법으로 나타나는 효과는 1. 비선형성의 증가로 인한 모델의 식별 능력이 증가 2. 학습해야 하는 파라미터 수가 감소 이다. 7x7 = 49 vs (3 x 3) x 3 =27
- 그림에서 보듯이 합성곱 계층을 2-4회 연속으로 풀링 계층을 두어 크기를 절반으로 줄이는 처리를 반복하고 마지막에는 fully-connected layer을 통과시켜 결과를 출력한다.

4. GoogLeNet
: 세로 방향 깊이 뿐만 아니라 가로 방향도 깊다는 것이 특징 -> 인셉션 구조

1) Aggressive Stem
: Input 이미지가 고해상도이니깐 연산을 낮추기 위해 빠르게 downsampling

2) Inception Module
- GoogLeNet은 총 9개의 인셉션 모듈을 포함하고 있다.
- 1x1 convolution을 포함하여 이는 특성맵의 피쳐를 줄여주는 역할을 한다.
- 이전 CNN모델들은 한 층에서 동일한 사이즈의 필터커널을 이용해서 컨볼루션 해줬던 것과 다르게, GoogLeNet에서는 이전 층에서 생성된 특성맵을 1x1 컨볼루션, 3x3 컨볼루션, 5x5 컨볼루션, 3x3 최대풀링해준 결과 얻은 특성맵들을 모두 함께 쌓아준다.

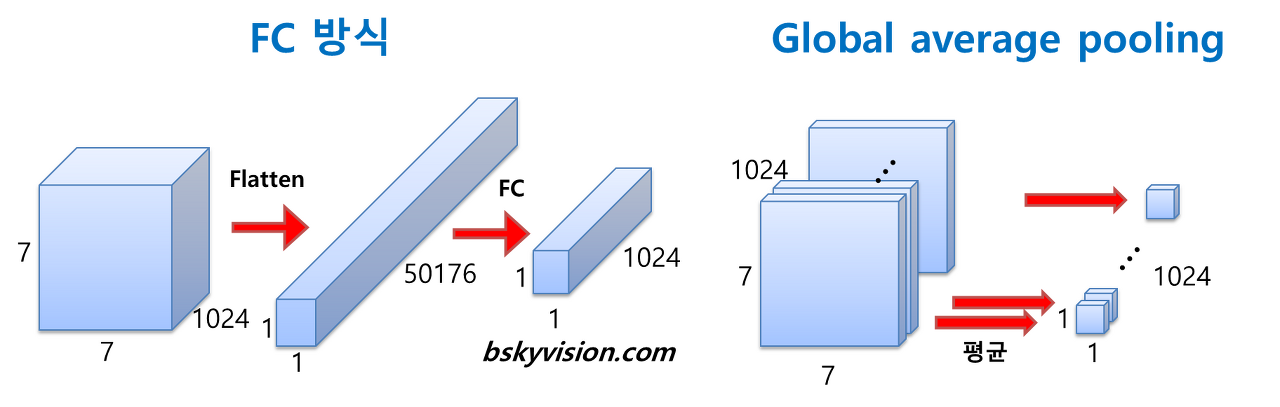
3) Global Average Pooling
: 전 층에서 산출된 특성맵들을 각각 평균낸 것을 이어서 1차원 벡터를 만들어주는 것이다.
(1차원 벡터를 만들어줘야 최종적으로 이미지 분류를 위한 softmax 층을 연결할 수 있기 때문에)
이렇게 해서 얻는 장점은 가중치의 갯수를 상당히 많이 없애준다는 것이다.

4) Auxiliary Classifiers
네트워크가 깊어질 수록 vanishing gradient 문제를 피하기 어려워진다. 그래서 GoogLeNet에서는 네트워크 중간에 두개의 보조 분류기를 달아주었다.

5. Residual Networks (ResNet)
: 스킵연결을 사용하여 입력 데이터를 합성곱 계층을 건너뛰어 출력에 바로 더한다.
+ Shortcut connection 추가해주게 되면 이전으로부터 얼만큼 변하는지 나머지(residual)만 계산하는 문제로 바뀜. 현재 레이어의 출력값과 이전 레이어 출력값을 더해 입력을 받기 때문에 그 차이를 볼 수 있게 됨. 따라서 더 빠르게 학습

Basic Block vs Bottleneck Block

- Residual 구조에서 [1x1 -> 3x3 -> 1x1] 구조를 이용하여 Bottoleneck 구조를 만들어 냈고 Dimension의 Reduction과 Expansion 효과를 주어 연산 시간 감소 성능을 얻을 수 있다.
- Improving Residual Networks : Block Design
< 정리>
Top-1 accuracy가 가장 높은 것은 Inception-v4: Resnet + Inception
▶ VGG : Highest memory, most operations
▶ GoogLeNet : Very efficient!
▶ AlexNet : Low compute, lots of parameters
▶ ResNet : Simple design, moderate efficiency, high accuracy
7. Improving ResNets : ResNeXt

8. Advance
- Model Ensembles
- Grouped Convolution
- Squeeze-and- Excitation Networks
- Densely Connected Neural Networks
- MobileNets : Tiny Networks (For Mobile Devices)
- Neural Architecture Search
9. Summary


'Open Lecture Review > Deep Learning for Computer Vision' 카테고리의 다른 글
| Lecture 11_Training Neural Networks 2 (0) | 2022.02.13 |
|---|---|
| Lec10_Training Neural Networks 1 (0) | 2022.02.07 |
| Lec7_ Convolutional Networks (0) | 2022.01.24 |
| Lec6_Backpropagation (0) | 2022.01.24 |
| Lec5_Neural Networks (0) | 2022.01.14 |



